추천 시스템의 목표는 '사용자'에게 그가 관심을 가질만한 '상품'을 능동적으로 제시해주는 것이죠. 즉, 추천 시스템에서는 유저(user)와 아이템(item)이 중요한 역할을 차지합니다. 이 중 '유저'에 대한 정보를 활용하는 인구통계학적 필터링(Demographic Filtering)에 대해 지난 포스팅에서 알아봤는데요. 이번 글에서는 '아이템'에 대한 정보를 활용하는 접근법인 컨텐츠 기반 필터링(Content-based Filtering)에 대해서 이야기해보겠습니다. ت
인풋 데이터 만들기
'아이템에 대한 정보'라 하면 어떤 것들이 떠오르시나요?
조금 더 쉽게 떠올리실 수 있도록 '수달이'에게 '영화'를 추천해주는 상황을 가정하고, 저의 ❤인생 영화❤인 '라라 랜드'를 예로 들어 이야기해보겠습니다. 아래의 사진은 네이버 영화에서 '라라 랜드'를 검색했을 때 나오는 페이지인데요. 여기서 볼 수 있는 모든 정보들이 추천 시스템에 활용될 수 있습니다. 장르, 제작 국가, 감독, 출연 배우, 등급 등 영화에 대한 기본 정보는 물론이고, 성별/나이별 관람추이 같은 숫자형 정보도 활용할 수 있습니다.

그리고 이러한 정보들을 데이터 사이언스 용어로는 feature라고 부르는데요. 이제 영화에 대한 feature에 어떤 것을 포함할 수 있는지 알았으니, 추천 시스템을 학습시키기 위해 필요한 인풋 데이터를 만들어보도록 하겠습니다. 우선, 테이블 형태의 정형화된 데이터 형식을 가정하고, 테이블의 행에는 영화의 제목을, 열에는 feature를 나열하도록 하겠습니다. 그리고 각 셀에는 해당하는 영화의 feature를 기입하여 완성합니다. 아래 그림의 왼쪽 테이블처럼요.
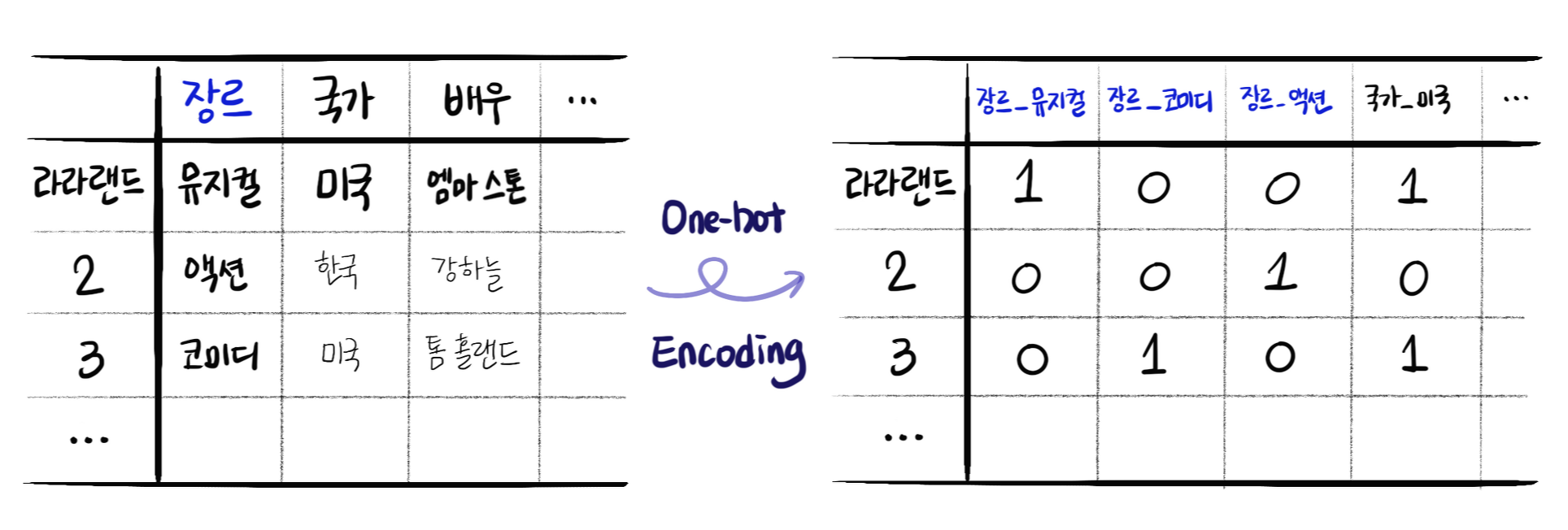
하지만 이런 텍스트 형태는 기계가 이해하기 힘들기 때문에 숫자로 변환해 주는 작업을 거쳐야 합니다. 예를 들어, '장르'라는 feature에 뮤지컬, 액션, 코미디라는 세 카테고리가 존재한다면, '장르_뮤지컬' '장르_액션' '장르_코미디'와 같이 각 카테고리를 단독적인 feature로 만들어줍니다. 그리고 해당 장르에 속하면 1로, 그렇지 않으면 0의 값을 부여합니다. 이러한 과정은 one-hot-encoding, 원-핫 인코딩이라고 불립니다.
이렇게 텍스트를 숫자로 변환하는 과정을 거치고 나면, 우리는 각 영화를 영화제목 대신 n개의 feature로 대신하여 표현할 수 있습니다. 기계에게 "'라라 랜드'와 비슷한 영화 찾아줘!"라고 하는 대신 "[ 1, 0, 0, 1, ... ]와 비슷한 영화 찾아줘!"라고 요청하는 것이죠.
자, 이제 다음 할 일은 유저 '수달이'에 대해서 파악하는 것입니다. 수달이에게 영화를 추천해주려면 우선 수달이의 취향을 알아야 하는데요. 이 취향은 수달이가 직접 프로필에 입력해둔 정보일 수도 있고, 시청 기록을 통해서 간접적으로 알아낼 수도 있습니다. 어떤 방식으로 정보를 얻던, 중요한 포인트는 수달이의 취향을 영화와 같은 방법으로 표현하는 것입니다. 즉, 방금 전 정의한 n개의 feature로 표현하는 것이죠. 이처럼 아이템과 유저를 동일한 feature를 이용하여 표현하게 되면, 우리는 선형대수학을 활용하여 아이템과 유저가 얼마나 서로 비슷한지 수학적으로 계산할 수 있게 됩니다.
벡터의 내적과 벡터 유사성
선형대수라고 하면 머리가 하얘질 수 있지만 알고보면 굉장히 간단합니다. 우선, 용어부터 정리하자면, 우리가 위에서 만들어 둔 n개의 feature는 n차원의 벡터 vector라고 부를 수 있습니다. ('인풋 데이터 테이블의 각 행이 벡터다'라고 생각하시면 쉽습니다.) 두 번째로 살펴볼 개념은 벡터의 내적 dot product입니다. 두 벡터의 내적은 각 벡터에서 동일한 위치에 있는 값들끼리 곱해준 후, 그 곱의 결과를 모두 더하여 구할 수 있습니다. 그리고 이 내적이 바로 두 벡터의 유사성(similarity)을 나타낼 수 있는 지표가 됩니다.

이해를 돕기 위해 2차원 평면상에 있는 두 벡터를 가정해보겠습니다. 위의 그림에서 우리는 벡터 A는 벡터 B와는 비슷하지만 벡터 C와는 굉장히 다른 아이라는 걸 직관적으로 알 수 있습니다. 이제 각 쌍의 내적을 구해보면, 서로 비슷한 '벡터 A - 벡터 B' 쌍의 내적이 서로 다른 '벡터 A - 벡터 C' 쌍의 내적보다 크다는 걸 확인할 수 있습니다.
이를 위의 영화 시나리오에 대입하자면, 두 내적에 공통적으로 등장하는 벡터 A는 사용자인 '수달이', 벡터 B/C는 서로 스타일이 굉장히 다른 두 영화에 해당합니다. 그리고 위의 계산처럼 '벡터 A - 벡터 B'의 내적이 더 큰 경우, 수달이는 B 영화와 더 유사한 성향을 보인다고 할 수 있고, 따라서 C 영화보다는 B 영화를 추천해주는 것이 수달이의 선택을 받을 가능성이 더 높을 것입니다.
요약하자면, 컨텐츠 기반 필터링은 유저와 아이템을 각각 n차원의 벡터로 표현하고, 유저-아이템 벡터 쌍 중에서 내적 값이 가장 큰 쌍을 골라 해당 아이템을 유저에게 추천하게 됩니다.
컨텐츠 기반 필터링의 장점과 단점
앞선 포스팅에서 다루었던 인구통계학적 필터링이 유저 "집단"의 취향을 고려했다면, 컨텐츠 기반 필터링은 유저 "개인"의 취향을 존중합니다. 그래서 조금 더 개인화된 추천이 가능하죠. 또 다른 장점은, 새로운 유저 B가 등장하더라도 A에게 추천을 하기 위해 작업해두었던 아이템 벡터들을 그대로 재활용할 수 있다는 측면에서 유저 확장성이 큽니다.
하지만 모든 모델이 그렇듯, 컨텐츠 기반 필터링의 경우에도 장점과 동시에 단점이 존재합니다. 우선, 좋은 추천 결과를 내놓기 위해서는 해당 분야에 대한 깊은 전문성이 필요합니다. 아이템에 대한 수많은 정보 속에서 어떤 것을 모델의 feature로 사용할 것인지는 순전히 모델을 만드는 사람의 재량 아래에 있기 때문이죠.
어떤 목적으로 사용하냐에 따라 다를 수도 있지만, 제가 생각하는 더 치명적인 단점은 유저에게 색다른 아이템을 추천할 수 없다는 점입니다. 매일매일 정갈한 한식만 먹다가 혀끝이 짜릿한 마라를 먹었을 때 색다른 즐거움을 느끼는 것처럼, 나의 평소 취향과는 다른 선택을 했는데 그게 딱 나와 맞아떨어졌을 때 사람들은 더 큰 재미를 느끼게 됩니다. 하지만 컨텐츠 기반 필터링은 유저의 취향과 매우 유사한 아이템들만 추천해주기 때문에 "새로운 발견" 측면에서는 뚜렷한 한계를 가지고 있습니다.
다음 포스팅: 조금 더 다양한 추천을 원한다면? 협업 필터링 (Collaborative Filtering)
컨텐츠 기반 필터링의 위와 같은 치명적인 단점을 극복할 수 있는 방법이 있습니다. 바로 협업 필터링 Collaborative Filtering이라 불리는 접근법인데요. '협업'이라는 단어가 힌트를 주는 것처럼, 이 접근법은 타겟 유저에 대한 정보뿐만 아니라 타 유저에 대한 정보를 동시에 활용하는 방법입니다. 그럼 글이 길어진 만큼, 이쯤에서 줄이고 다음 포스팅에서 새로운 접근법과 함께 만나 뵙도록 하겠습니다!
Happy Machine Learning! ت

컨텐츠 기반 필터링 Content-based Filtering
유저와 아이템을 각각 n차원의 벡터로 표현하고, 유저-아이템 벡터 쌍 중에서 내적 값이 가장 큰 쌍을 골라 해당 아이템을 유저에게 추천한다.
'추천 시스템 | Recommender System' 카테고리의 다른 글
| 추천 시스템 06. Matrix Factorization 행렬 분해 (1) | 2022.03.25 |
|---|---|
| 추천 시스템 05. Item-based Collaborative Filtering 아이템 기반 협업 필터링 (0) | 2022.02.02 |
| 추천 시스템 04. User-based Collaborative Filtering 유저 기반 협업 필터링 (0) | 2022.01.14 |
| 추천 시스템 02. Demographic Filtering 인구통계학적 필터링 (0) | 2021.12.08 |
| 추천 시스템 01. Recommender System의 큰 갈래 알아보기 (2) | 2021.12.08 |



